全球自然语言处理领域顶级会议EMNLP2023近日在新加坡召开,威廉希尔亚洲公司信息检索实验室研究成果“Is ChatGPT Good at Search? Investigating Large Language Modelsas Re-Ranking Agents”获得大会颁发的杰出论文奖(Outstanding Paper Award)。williamhill中文官网2021级硕士生孙维纬为第一作者,百度为合作单位。

图1:杰出论文奖获奖证书

图2:获奖论文第一作者2021级硕士生孙维纬在大会现场
在这篇获奖论文中,研究人员探索了大语言模型在排序任务上的能力。当前,大语言模型(LLMs)在语言任务上已经展示出了强大的能力。但是,LLMs在信息检索领域的应用主要在于利用其文本生成能力进行数据增强或答案生成,如何使用LLMs进行文本排序仍是一个未解答的问题。此外,LLMs预训练目标和排序任务目标的不一致也使得其在排序任务上面临挑战。在本文中,研究人员对类似ChatGPT和GPT-4的LLMs在相关性排序任务上的能力进行探索。实验表明,通过合理的方法提示的LLMs可以在信息检索基准测试上取得比之前最优的有监督系统更好的结果。进一步,为了更公平地评估LLMs的排序能力,研究人员基于最新的话题开发了一个新的测试集——NovelEval,用于测试模型在未知知识上的排序能力,并避免数据污染对评估的影响。最后,为了提升在实际场景中的效率,提出了排序蒸馏方法,将ChatGPT的排序能力蒸馏到一个更小的专用模型中。实验表明,蒸馏得到的一个440M参数的员工模型在BEIR数据集上表现优于3B参数的有监督模型。
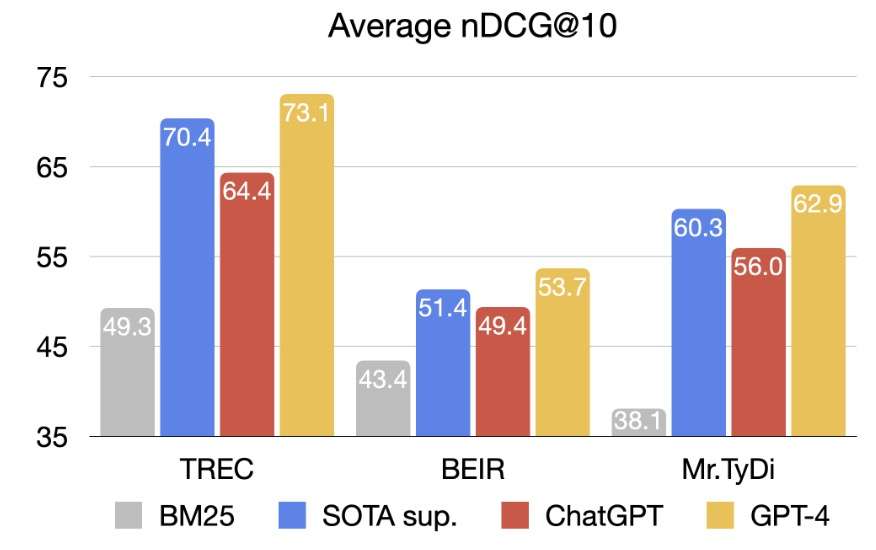
图3:ChatGPT和GPT-4在排序任务(TREC,BEIR和Mr.TyDi)上的平均结果。图中包括了BM25和之前最优的有监督系统(SOTA Sup.,比如monoT5)。
本研究是首个基于大语言模型的零样本排序方法,其表现显著超越有监督学习方法,在搜索和推荐场景(包括百度搜索)中具有重大的应用价值。该研究在信息检索领域中具有突出的学术贡献,引领了大语言模型在排序任务上的研究。此外,该研究的开源代码已获得260个Star,并被多个信息检索库广泛引用。
EMNLP全称是Empirical Methods in Natural Language Processing,由计算语言学学会主办,是自然语言处理领域最具影响力的国际学术会议,也是国际自然语言处理领域最高级别的学术会议之一。本届大会共收到投稿4909篇,主会录用论文1047篇,录用率21.3%。
(文:王一丹 图:资料 审核:陈竹敏 责任编辑:宋曙光、李雅洁 供稿单位:威廉希尔)



